
“AI 뇌”를 통한 하이 레벨 자율주행


시각-언어-액션 모델
DeepRoute.ai의 스마트 자율주행 시스템은 VLA를 통해 시각, 언어
액션을 연결하여, 운행 중 발생하는 복잡한 교차 정보와 숨겨진 언어 정보 및 논리적 추론을 이해할 수 있으며
효율적인 장면 범화능력과 안정적인 주행 성능을 갖추고 있습니다.





End-to-end Model
End-to-End 모델을 기반으로, 감지 및 예측
계획 등 모델을 통합하여
정보가 서로 다른 모델 간 전달 시 발생하는 손실을 방지하고, 센서 신호 입력 후 바로 동작 제어가 가능한 기술을 실현하였고
방대한 데이터를 사용하여 시스템을 훈련시켜 기계가 자율학습
사고 및 분석 능력을 갖춰 복잡한 주행 임무를 처리할 수 있도록 실현







-
Localization
-
Mapping
-
Control
-
Planning
-
Decision
-
Prediction
-
Late fusion
-
Object tracking
-
Detection
-
Control
-
Multi-sensor fusion
-
Planning
-
Decision
-
Localization
-
Mapping
-
Prediction
-
Control

Prediction Planning Net
-
General Perception Net
Deploy VLA Model on consumer cars
Initial road test of end-to-end model
Rule-based
More engineering, adequate data
Learning-based
Less engineering, more data
데이터 폐쇄 루프
맵 회사 지원을 통해 데이터 라벨링, 클리닝, 라벨 설정, 분류, 품질 검사, 모델 훈련, 테스트 검증 등 절차를 갖추었고, 지속적으로 학습하는 데이터 폐쇄 루프를 형성해 자율주행 시스템이 지속적으로 자동 최적화 업데이트
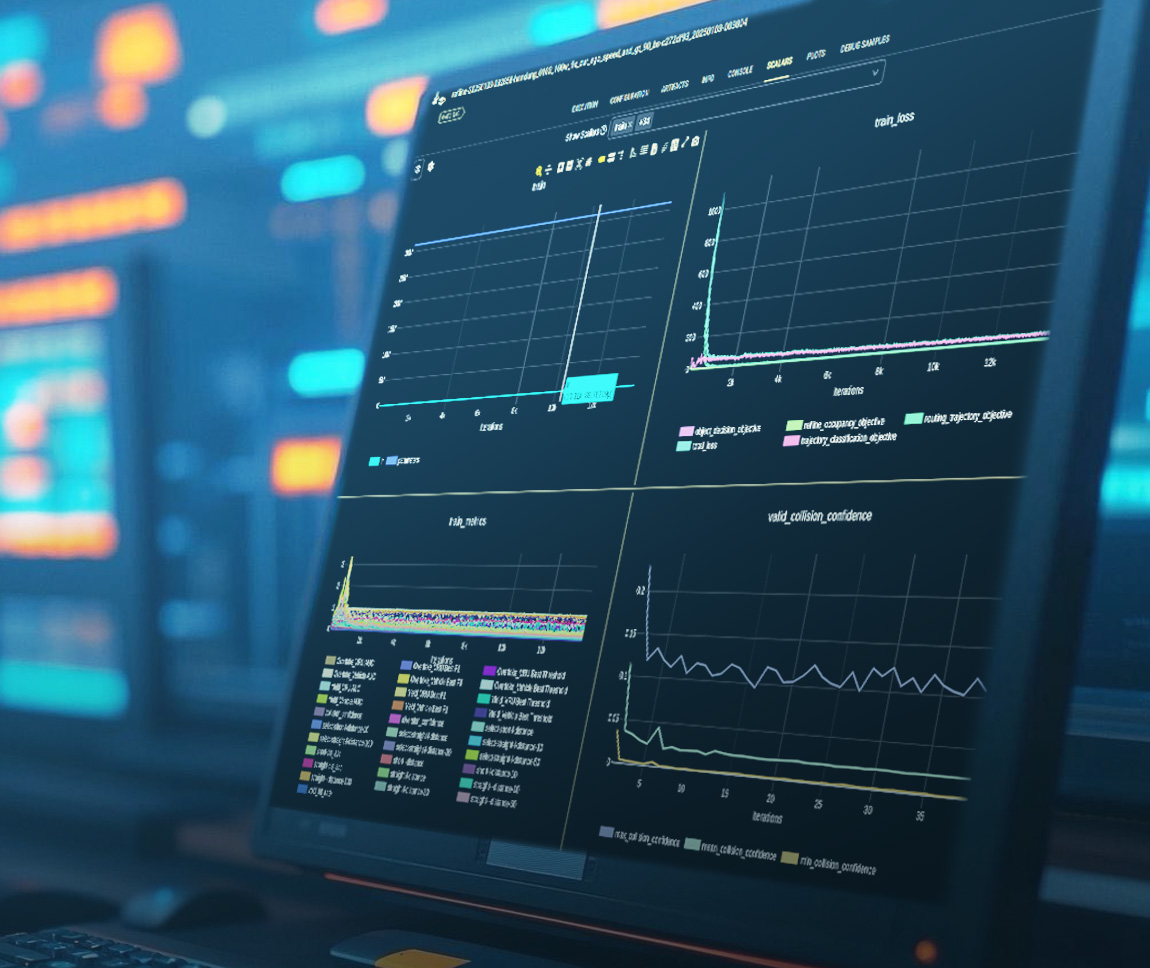
모델 훈련

방대한 양질의 데이터
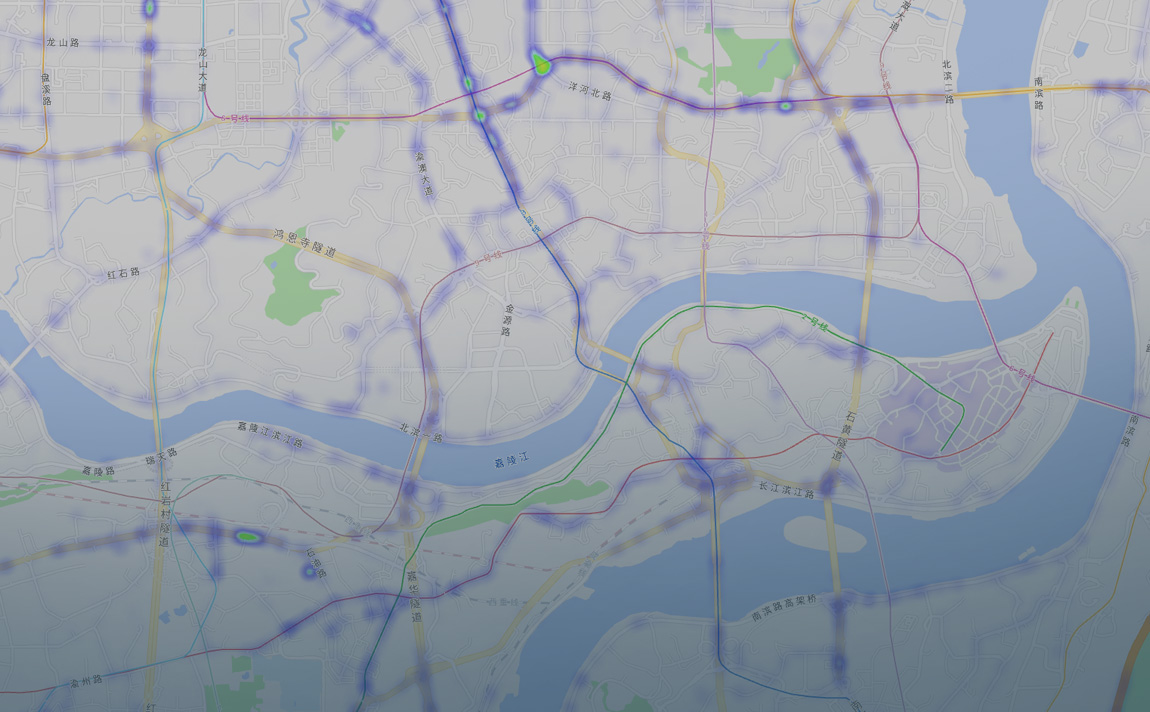
데이터 발굴